Custom data handlers for common ML datasets
This folder contains data loaders for common datasets. Note, the code in this folder is a derivative of the dataloaders developed in this repo. For examples on how to use these data loaders with Tensorflow checkout the original code.
All dataloaders are derived from the abstract base class hypnettorch.data.dataset.Dataset to provide a common API to the user.
Preparation of datasets
Datasets not mentioned in this section will be automatically downloaded and processed.
Here you can find instructions about how to prepare some of the datasets for automatic processing.
Large-scale CelebFaces Attributes (CelebA) Dataset
CelebA is a dataset with over 200K celebrity images. It can be downloaded from here.
Google Drive will split the dataset into multiple zip-files. In the following, we explain, how you can extract these files on Linux. To decompress the sharded zip files, simply open a terminal, move to the downloaded zip-files and enter:
$ unzip '*.zip'
This will create a local folder named CelebA.
Afterwards move into the Img subfolder:
$ cd ./CelebA/Img/
You can now decide, whether you want to use the JPG or PNG encoded images.
For the jpeg images, you have to enter:
$ unzip img_align_celeba.zip
This will create a folder img_align_celeba, containing all images in jpeg format.
To save space on your local machine, you may delete the zip file via rm img_align_celeba.zip.
The same images are also available in png format. To extract these, you have to move in the corresponding subdirectory via cd img_align_celeba_png.7z. You can now extract the sharded 7z files by entering:
$ 7z e img_align_celeba_png.7z.001
Again, you may now delete the archives to save space via rm img_align_celeba_png.7z.0*.
You can proceed similarly if you want to work with the original images located in the folder img_celeba.7z.
FYI, there are scripts available (e.g., here), that can be used to download the dataset.
Imagenet Large Scale Visual Recognition Challenge 2012 (ILSVRC2012)
The ILSVRC2012 dataset is a subset of the ImageNet dataset and contains over 1.2 Mio. training images depicting natural image scenes of 1,000 object classes. The dataset can be downloaded here here.
For our program to be able to use the dataset, it has to be prepared as described here.
In the following, we recapitulate the required steps (which are executed from the directory in which the dataset has been loaded to).
Download the training and validation images as well as the development kit for task 1 & 2.
Extract the training data.
mkdir train && mv ILSVRC2012_img_train.tar train/ && cd train tar -xvf ILSVRC2012_img_train.tar && rm -f ILSVRC2012_img_train.tar find . -name "*.tar" | while read NAME ; do mkdir -p "${NAME%.tar}"; tar -xvf "${NAME}" -C "${NAME%.tar}"; rm -f "${NAME}"; done cd ..
Note, this step deletes the the downloaded tar-file. If this behavior is not desired replace the command
rm -f ILSVRC2012_img_train.tarwithmv ILSVRC2012_img_train.tar ...Extract the validation data and move images to subfolders.
mkdir val && mv ILSVRC2012_img_val.tar val/ && cd val && tar -xvf ILSVRC2012_img_val.tar wget -qO- https://raw.githubusercontent.com/soumith/imagenetloader.torch/master/valprep.sh | bash cd ..
This step ensures that the validation samples are grouped in the same folder structure as the training samples, i.e., validation images are stored under their corresponding WordNet ID (WNID).
Extract the meta data:
mkdir meta && mv ILSVRC2012_devkit_t12.tar.gz meta/ && cd meta && tar -xvzf ILSVRC2012_devkit_t12.tar.gz --strip 1 cd ..
Udacity Steering Angle Prediction
The CH2 steering angle prediction dataset from Udacity can be downloaded here. In the following, we quickly explain how we expect the downloads to be preprocessed for our datahandler to work.
You may first decompress the files, after which you should have two subfolders Ch2_001 (for the test data) and ``Ch2_002 (for the training data). You may replace the file Ch2_001/HMB_3_release.bag with the complete test set Ch2_001/HMB_3.bag.
We use this docker tool to extract the information from the Bag files and align the steering information with the recorded images.
Simply clone the repository and execute the ./build.sh. This issue helped us to overcome an error during the build.
Afterwards, the bagfiles can be extracted using (note, that in- and output directory must be specified using absolute paths), for instance
sudo ./run-bagdump.sh -i /data/udacity/Ch2_001/ -o /data/udacity/Ch2_001/
and
sudo ./run-bagdump.sh -i /data/udacity/Ch2_002/ -o /data/udacity/Ch2_002/
The data handler only requires the center/ folder and the file interpolated.csv. All remaining extracted data (for instance, left and right camera images) can be deleted.
Alternatively, the dataset can be downloaded from here. This dataset appears to contain images recorded a month before the official Challenge 2 dataset was recorded. We could not find any information whether the experimental conditions are identical (e.g., whether steering angles are directly comparable). Additionally, the dataset appears to contain situations like parking, where the vehicle doesn’t move and there is no road ahead. Anyway, if desired, the dataset can be processed similarly to the above mentioned. One may first want to filter the bag file, to only keep information relevant for the task at hand, e.g.:
rosbag filter dataset-2-2.bag dataset-2-2_filtered.bag "topic == '/center_camera/image_color' or topic == '/vehicle/steering_report'"
The bag file can be extracted in to center/ folder and a file interpolated.csv as described above, using ./run-bagdump.sh.
API
Dataset Interface
The module data.dataset contains a template for a dataset interface,
that can be used to feed data into neural networks.
The implementation is based on an earlier implementation of a class I used in another project:
At the moment, the class holds all data in memory and is therefore not meant
for bigger datasets. Though, it is easy to design wrappers that overcome this
limitation (e.g., see abstract base class
data.large_img_dataset.LargeImgDataset).
Get unique identifiers all test samples. |
|
Get unique identifiers all training samples. |
|
Get unique identifiers all validation samples. |
|
Get the inputs of all test samples. |
|
Get the outputs (targets) of all test samples. |
|
Get the inputs of all training samples. |
|
Get the outputs (targets) of all training samples. |
|
Get the inputs of all validation samples. |
|
Get the outputs (targets) of all validation samples. |
|
|
This method can be used to map the internal numpy arrays to PyTorch tensors. |
Are input (resp. |
|
Return the next random test batch. |
|
Return the next random training batch. |
|
Return the next random validation batch. |
|
A generator to loop over the test set. |
|
A generator to loop over the training set. |
|
A generator to loop over the validation set. |
|
|
Similar to method |
Plot samples belonging to this dataset. |
|
|
The batch generation possesses a memory. |
This method should be used by the map function of the Tensorflow Dataset interface ( |
|
Similar to method |
|
Translate an array of test sample identifiers to test indices. |
|
Translate an array of training sample identifiers to training indices. |
|
Translate an array of validation sample identifiers to validation indices. |
- class hypnettorch.data.dataset.Dataset[source]
Bases:
ABCA general dataset template that can be used as a simple and consistent interface. Note, that this is an abstract class that should not be instantiated.
In order to write an interface for another dataset, you have to implement an inherited class. You must always call the constructor of this base class first when instantiating the implemented subclass.
Note, the internals are stored in the private member
_data, that is described in the constructor.- abstract get_identifier()[source]
Returns the name of the dataset.
- Returns:
The dataset its (unique) identifier.
- Return type:
(str)
- get_test_ids()[source]
Get unique identifiers all test samples.
See documentation of method
get_train_ids()for details.- Returns:
A 1D numpy array.
- Return type:
- get_test_inputs()[source]
Get the inputs of all test samples.
See documentation of method
get_train_inputs()for details.- Returns:
A 2D numpy array.
- Return type:
- get_test_outputs(use_one_hot=None)[source]
Get the outputs (targets) of all test samples.
See documentation of method
get_train_outputs()for details.- Parameters:
(....) – See docstring of method
get_train_outputs().- Returns:
A 2D numpy array.
- Return type:
- get_train_ids()[source]
Get unique identifiers all training samples.
Each sample in the dataset has a unique identifier (independent of the dataset split it is assigned to).
Note
Sample identifiers do not correspond to the indices of samples within a dataset split (i.e., the returned identifiers of this method cannot be used as indices for the returned arrays of methods
get_train_inputs()andget_train_outputs())- Returns:
A 1D numpy array containing the unique identifiers for all training samples.
- Return type:
- get_train_inputs()[source]
Get the inputs of all training samples.
Note, that each sample is encoded as a single vector. One may use the attribute
in_shapeto decode the actual shape of an input sample.- Returns:
A 2D numpy array, where each row encodes a training sample.
- Return type:
- get_train_outputs(use_one_hot=None)[source]
Get the outputs (targets) of all training samples.
Note, that each sample is encoded as a single vector. One may use the attribute
out_shapeto decode the actual shape of an output sample. Keep in mind, that classification samples might be one-hot encoded.- Parameters:
use_one_hot (bool) – For classification samples, the encoding of the returned samples can be either “one-hot” or “class index”. This option is ignored for datasets other than classification sets. If
None, the dataset its default encoding is returned.- Returns:
A 2D numpy array, where each row encodes a training target.
- Return type:
- get_val_ids()[source]
Get unique identifiers all validation samples.
See documentation of method
get_train_ids()for details.- Returns:
A 1D numpy array. Returns
Noneif no validation set exists.- Return type:
- get_val_inputs()[source]
Get the inputs of all validation samples.
See documentation of method
get_train_inputs()for details.- Returns:
A 2D numpy array. Returns
Noneif no validation set exists.- Return type:
- get_val_outputs(use_one_hot=None)[source]
Get the outputs (targets) of all validation samples.
See documentation of method
get_train_outputs()for details.- Parameters:
(....) – See docstring of method
get_train_outputs().- Returns:
A 2D numpy array. Returns
Noneif no validation set exists.- Return type:
- property in_shape
The original shape of an input sample.
Note, that samples are encoded by this class as individual vectors (e.g., an MNIST sample is ancoded as 784 dimensional vector, but its original shape is:
[28, 28, 1]). A sequential sample is encoded by concatenating all timeframes. Hence, the number of timesteps can be decoded by dividing a single sample vector bynp.prod(in_shape).- Type:
- input_to_torch_tensor(x, device, mode='inference', force_no_preprocessing=False, sample_ids=None)[source]
This method can be used to map the internal numpy arrays to PyTorch tensors.
Note, subclasses might overwrite this method and add data preprocessing/ augmentation.
- Parameters:
x (numpy.ndarray) – A 2D numpy array, containing inputs as provided by this dataset.
device (torch.device or int) – The PyTorch device onto which the input should be mapped.
mode (str) – See docstring of method
tf_input_map(). Valid values are:trainandinference.force_no_preprocessing (bool) – In case preprocessing is applied to the inputs (e.g., normalization or random flips/crops), this option can be used to prohibit any kind of manipulation. Hence, the inputs are transformed into PyTorch tensors on an “as is” basis.
sample_ids (numpy.ndarray) – See method
train_ids_to_indices(). Instantiation of this class might make use of this information, for instance in order to reduce the amount of zero padding within a mini-batch.
- Returns:
The given input
xas PyTorch tensor.- Return type:
- is_image_dataset()[source]
Are input (resp. output) samples images?
Note, for sequence datasets, this method just returns whether a single frame encodes an image.
- Returns:
Tuple containing two booleans:
input_is_img
output_is_img
- Return type:
(tuple)
- property is_one_hot
Whether output labels are one-hot encoded for a classification task (
Noneotherwise).- Type:
bool or None
- next_test_batch(batch_size, use_one_hot=None, return_ids=False)[source]
Return the next random test batch.
See documentation of method
next_train_batch()for details.- Parameters:
(....) – See docstring of method
next_train_batch().- Returns:
List containing the following 2D numpy arrays:
batch_inputs
batch_outputs
batch_ids (optional)
- Return type:
(list)
- next_train_batch(batch_size, use_one_hot=None, return_ids=False)[source]
Return the next random training batch.
If the behavior of this method should be reproducible, please define a numpy random seed.
- Parameters:
(....) – See docstring of method
get_train_outputs().batch_size (int) – The size of the returned batch.
return_ids (bool) –
If
True, a third value will be returned that is a 1D numpy array containing sample identifiers.Note
Those integer values are internal unique sample identifiers and in general do not correspond to indices within the corresponding dataset split (i.e., the training split in this case).
- Returns:
List containing the following 2D numpy arrays:
batch_inputs: The inputs of the samples belonging to the batch.
batch_outputs: The outputs of the samples belonging to the batch.
batch_ids (optional): See option
return_ident.
- Return type:
(list)
- next_val_batch(batch_size, use_one_hot=None, return_ids=False)[source]
Return the next random validation batch.
See documentation of method
next_train_batch()for details.- Parameters:
(....) – See docstring of method
next_train_batch().- Returns:
List containing the following 2D numpy arrays:
batch_inputs
batch_outputs
batch_ids (optional)
Returns
Noneif no validation set exists.- Return type:
(list)
- property num_classes
The number of classes for a classification task (
Noneotherwise).- Type:
int or None
- output_to_torch_tensor(y, device, mode='inference', force_no_preprocessing=False, sample_ids=None)[source]
Similar to method
input_to_torch_tensor(), just for dataset outputs.Note, in this default implementation, it is also does not perform any data preprocessing.
- Parameters:
(....) – See docstring of method
input_to_torch_tensor().- Returns:
The given output
yas PyTorch tensor.- Return type:
- plot_samples(title, inputs, outputs=None, predictions=None, num_samples_per_row=4, show=True, filename=None, interactive=False, figsize=(10, 6), **kwargs)[source]
Plot samples belonging to this dataset. Each sample will be plotted in its own subplot.
- Parameters:
title (str) – The title of the whole figure.
inputs (numpy.ndarray) – A 2D numpy array, where each row is an input sample.
outputs (numpy.ndarray, optional) – A 2D numpy array of actual dataset targets.
predictions (numpy.ndarray, optional) – A 2D numpy array of predicted output samples (i.e., output predicted by a neural network).
num_samples_per_row (int) – Maximum number of samples plotted per row in the generated figure.
show (bool) – Whether the plot should be shown.
filename (str, optional) – If provided, the figure will be stored under this filename.
interactive (bool) – Turn on interactive mode. We mainly use this option to ensure that the program will run in background while figure is displayed. The figure will be displayed until another one is displayed, the user closes it or the program has terminated. If this option is deactivated, the program will freeze until the user closes the figure. Note, if using the iPython inline backend, this option has no effect.
figsize (tuple) – A tuple, determining the size of the figure in inches.
**kwargs (optional) – Optional keyword arguments that can be dataset dependent.
- reset_batch_generator(train=True, test=True, val=True)[source]
The batch generation possesses a memory. Hence, the samples returned depend on how many samples already have been retrieved via the next- batch functions (e.g.,
next_train_batch()). This method can be used to reset these generators.- Parameters:
train (bool) – If
True, the generator fornext_train_batch()is reset.test (bool) – If
True, the generator fornext_test_batch()is reset.val (bool) – If
True, the generator fornext_val_batch()is reset, if a validation set exists.
- property sequence
Whether the dataset contains sequences (samples have temporal structure). In case of a sequential dataset, the temporal structure can be decoded via the shape attributes of in- and outputs. Note, that all samples are internally zero-padded to the same length.
- Type:
- property shuffle_test_samples
Whether the method
next_test_batch()returns test samples in random order at every epoch. Defaults toTrue, i.e., samples have a random ordering every epoch.- Type:
- Setter:
Note, setting this attribute will reset the current batch generator, such that the next call to the method
next_test_batch()results in starting a sweep through a new epoch (full batch).
- property shuffle_val_samples
Same as
shuffle_test_samplesfor samples from the validation set.- Type:
- test_ids_to_indices(sample_ids)[source]
Translate an array of test sample identifiers to test indices.
See documentation of method
train_ids_to_indices()for details.- Parameters:
(....) – See docstring of method
train_ids_to_indices().- Returns:
A 1D numpy array.
- Return type:
- test_iterator(batch_size, return_remainder=True, **kwargs)[source]
A generator to loop over the test set.
See documentation of method
train_iterator().- Parameters:
(....) – See docstring of method
train_iterator().- Yields:
(list) – The same list that would be returned by method
next_test_batch()but additionally prepended with the batch size.
- tf_input_map(mode='inference')[source]
This method should be used by the map function of the Tensorflow Dataset interface (
tf.data.Dataset.map). In the default case, this is just an identity map, as the data is already in memory.There might be cases, in which the full dataset is too large for the working memory, and therefore the data currently needed by Tensorflow has to be loaded from disk. This function should be used as an interface for this process.
- Parameters:
mode (str) – Is the data needed for training or inference? This distinction is important, as it might change the way the data is processed (e.g., special random data augmentation might apply during training but not during inference. The parameter is a string with the valid values being
trainandinference.- Returns:
A function handle, that maps the given input tensor to the preprocessed input tensor.
- Return type:
(function)
- tf_output_map(mode='inference')[source]
Similar to method
tf_input_map(), just for dataset outputs.Note, in this default implementation, it is also just an identity map.
- Parameters:
(....) – See docstring of method
tf_input_map().- Returns:
A function handle.
- Return type:
(function)
- train_ids_to_indices(sample_ids)[source]
Translate an array of training sample identifiers to training indices.
This method translates unique training identifiers (see method
get_train_ids()) to actual training indices, that can be used to index the training set.- Parameters:
sample_ids (numpy.ndarray) – 1D numpy array of unique sample IDs (e.g., those returned when using option
return_idsof methodnext_train_batch()).- Returns:
A 1D array of training indices that has the same length as
sample_ids.- Return type:
- train_iterator(batch_size, return_remainder=True, **kwargs)[source]
A generator to loop over the training set.
This generator yields the return value of
next_train_batch()prepended with the current batch size.Example
for batch_size, x, y in data.train_iterator(32): x_t = data.input_to_torch_tensor(x, device, mode='train') y_t = data.output_to_torch_tensor(y, device, mode='train') # ...
for batch_size, x, y, ids in data.train_iterator(32, \ return_ids=True): x_t = data.input_to_torch_tensor(x, device, mode='train') y_t = data.output_to_torch_tensor(y, device, mode='train') # ...
Note
This method will only temporarily modify the internal batch generator (see method
reset_batch_generator()) until the epoch is completed.- Parameters:
batch_size (int) –
The batch size used.
Note
If
batch_sizeis not an integer divider ofnum_train_samples, then the last yielded batch will be smaller ifreturn_remainderisTrue.return_remainder (bool) –
The last batch might have to be smaller if
batch_sizeis not an integer divider ofnum_train_samples. If this attribute isFalse, this last part is not yielded and all batches have the same size.Note
If
return_remainderis se ttoFalse, then it may be that not all training samples are yielded.**kwargs – Keyword arguments that are passed to method
next_train_batch().
- Yields:
(list) – The same list that would be returned by method
next_train_batch()but additionally prepended with the batch size.
- val_ids_to_indices(sample_ids)[source]
Translate an array of validation sample identifiers to validation indices.
See documentation of method
train_ids_to_indices()for details.- Parameters:
(....) – See docstring of method
train_ids_to_indices().- Returns:
A 1D numpy array.
- Return type:
- val_iterator(batch_size, return_remainder=True, **kwargs)[source]
A generator to loop over the validation set.
See documentation of method
train_iterator().- Parameters:
(....) – See docstring of method
train_iterator().- Yields:
(list) – The same list that would be returned by method
next_val_batch()but additionally prepended with the batch size.
Wrapper for large image datasets
The module data.large_img_dataset contains an abstract wrapper for large
datasets, that have images as inputs. Typically, these datasets are too large to
be loaded into memory. Though, their outputs (labels) can still easily be hold
in memory. Hence, the idea is, that instead of loading the actual images, we
load the paths for each image into memory. Then we can load the images from disk
as needed.
To sum up, handlers that implement this interface will hold the outputs and paths for the input images of the whole dataset in memory, but not the actual images.
As an alternative, one can implement wrappers for HDF5 and TFRecord files.
Here is a simple example that illustrates the format of the dataset:
In case of working with PyTorch, rather than using the internal methods for
batch processing (such as data.dataset.Dataset.next_train_batch()) one
should adapt PyTorch its data processing utilities (consisting of
torch.utils.data.Dataset and torch.utils.data.DataLoader)
in combination with class attributes such as
data.large_img_dataset.LargeImgDataset.torch_train.
- class hypnettorch.data.large_img_dataset.LargeImgDataset(imgs_path, png_format=False)[source]
Bases:
DatasetA general dataset template for datasets with images as inputs, that are locally stored as individual files. Note, that this is an abstract class that should not be instantiated.
Hints, when implementing the interface:
Attribute
data.dataset.Dataset.in_shapestill has to be correctly implemented, independent of the fact, that the actual input data is a list of strings.
- Parameters:
imgs_path (str) – The path to the folder, containing the image files (the actual image paths contained in the input data (see e.g.,
data.dataset.Dataset.get_train_inputs()) will be concatenated to this path).png_format (bool) – The images are typically assumed to be jpeg encoded. You may change this to png enocded images.
- get_test_inputs()[source]
Get the inputs of all test samples.
- Returns:
An np.chararray, where each row corresponds to an image file name.
- Return type:
- get_train_inputs()[source]
Get the inputs of all training samples.
- Returns:
An np.chararray, where each row corresponds to an image file name.
- Return type:
- get_val_inputs()[source]
Get the inputs of all validation samples.
- Returns:
An np.chararray, where each row corresponds to an image file name. If no validation set exists,
Nonewill be returned.- Return type:
- input_to_torch_tensor(x, device, mode='inference', force_no_preprocessing=False, sample_ids=None)[source]
Note, this method has been overwritten from the base class. It should not be used for large image datasets. Instead, the class should provide instances of class
torch.utils.data.Datasetfor training, validation and test set:
- read_images(inputs)[source]
For the given filenames, read and return the images.
- Parameters:
inputs (numpy.chararray) – An np.chararray of filenames.
- Returns:
A 2D numpy array, where each row contains a picture.
- Return type:
- tf_input_map(mode='inference')[source]
Note, this method has been overwritten from the base class.
It provides a function handle that loads images from file, resizes them to match the internal input image size and then flattens the image to a vector.
- Parameters:
(....) – See docstring of method
data.dataset.Dataset.tf_input_map().- Returns:
A function handle, that maps the given input tensor to the preprocessed input tensor.
- Return type:
(function)
- property torch_test
The PyTorch compatible test dataset.
- Type:
- property torch_train
The PyTorch compatible training dataset.
- Type:
- property torch_val
The PyTorch compatible validation dataset.
- Type:
Wrapper for sequential datasets
The module data.sequential_dataset contains an abstract wrapper for
datasets containing sequential data.
Even though the dataset interface data.dataset.Dataset contains basic
support for sequential datasets, this wrapper was considered necessary to
increase the convinience when working with sequential datasets (especially,
if those datasets contain sequences of varying lengths).
- class hypnettorch.data.sequential_dataset.SequentialDataset[source]
Bases:
DatasetA general wrapper for datasets with sequential inputs and outpus.
- get_in_seq_lengths(sample_ids)[source]
Get the unpadded input sequence lengths for given samples.
- Parameters:
sample_ids (numpy.ndarray) – A 1D numpy array of unique sample identifiers. Please see documentation of option
return_idsof methoddata.dataset.Dataset.next_train_batch()as well as methoddata.dataset.Dataset.get_train_ids()for more information of sample identifiers.- Returns:
A 1D array of the same length as
sample_idscontaining the unpadded input sequence lengths of these samples.- Return type:
- get_out_seq_lengths(sample_ids)[source]
Get the unpadded output sequence lengths for given samples.
See documentation of method
get_in_seq_lengths().- Parameters:
(....) – See docstring of method
get_in_seq_lengths().- Returns:
A 1D numpy array.
- Return type:
- input_to_torch_tensor(x, device, mode='inference', force_no_preprocessing=False, sample_ids=None)[source]
This method can be used to map the internal numpy arrays to PyTorch tensors.
- Parameters:
(....) – See docstring of method
data.dataset.Dataset.input_to_torch_tensor().- Returns:
The given input
xas PyTorch tensor. It has dimensions[T, B, *in_shape], whereTis the number of time steps (see attributemax_num_ts_in),Bis the batch size andin_shaperefers to the input feature shape, seedata.dataset.Dataset.in_shape.- Return type:
- property max_num_ts_in
The maximum number of timesteps input sequences may have.
Note
Internally, all input sequences are stored according to this length using zero-padding.
- Type:
- property max_num_ts_out
The maximum number of timesteps output sequences may have.
Note
Internally, all input sequences are stored according to this length using zero-padding.
- Type:
- output_to_torch_tensor(y, device, mode='inference', force_no_preprocessing=False, sample_ids=None)[source]
Similar to method
input_to_torch_tensor(), just for dataset outputs.- Parameters:
(....) – See docstring of method
data.dataset.Dataset.output_to_torch_tensor().- Returns:
The given input
xas PyTorch tensor. It has dimensions[T, B, *out_shape], whereTis the number of time steps (see attributemax_num_ts_out),Bis the batch size andout_shaperefers to the output feature shape, seedata.dataset.Dataset.out_shape.- Return type:
CelebA Dataset
The module data.celeba_data contains a handler for the CelebA dataset.
- More information about the dataset can be retrieved from:
Note, in the current implementation, this handler will not download and extract the dataset for you. You have to do this manually by following the instructions of the README file (which is located in the same folder as this file).
Note, this dataset has not yet been prepared for PyTorch use!
- class hypnettorch.data.celeba_data.CelebAData(data_path, use_png=False, shape=None)[source]
Bases:
LargeImgDatasetAn instance of the class shall represent the CelebA dataset.
The input data of the dataset will be strings to image files. The output data will be vectors of booleans, denoting whether a certain type of attribute is present in the picture.
Note
The dataset has to be already downloaded and extracted before this class can be instantiated. See the local README file for details.
- Parameters:
CIFAR-10 Dataset
The module data.cifar10_data contains a handler for the CIFAR 10 dataset.
The dataset consists of 60000 32x32 colour images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images.
- Information about the dataset can be retrieved from:
- class hypnettorch.data.cifar10_data.CIFAR10Data(data_path, use_one_hot=False, use_data_augmentation=False, validation_size=5000, use_cutout=False)[source]
Bases:
DatasetAn instance of the class shall represent the CIFAR-10 dataset.
Note, the constructor does not safe a data dump (via pickle) as, for instance, the MNIST data handler (
data.mnist_data.MNISTData) does. The reason is, that the downloaded files are already in a nice to read format, such that the time saved to read the file from a dump file is minimal.Note
By default, input samples are provided in a range of
[0, 1].- Parameters:
data_path (str) – Where should the dataset be read from? If not existing, the dataset will be downloaded into this folder.
use_one_hot (bool) – Whether the class labels should be represented in a one-hot encoding.
use_data_augmentation (bool) –
Note, this option currently only applies to input batches that are transformed using the class member
input_to_torch_tensor()(hence, only available for PyTorch, so far).Note
If activated, the statistics of test samples are changed as a normalization is applied.
validation_size (int) – The number of validation samples. Validation samples will be taking from the training set (the first
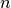 samples).
samples).use_cutout (bool) –
Whether option
apply_cutoutshould be set of methodtorch_input_transforms(). We use cutouts of size16 x 16as recommended here.Note
Only applies if
use_data_augmentationis set.
- input_to_torch_tensor(x, device, mode='inference', force_no_preprocessing=False, sample_ids=None)[source]
This method can be used to map the internal numpy arrays to PyTorch tensors.
Note, this method has been overwritten from the base class.
The input images are preprocessed if data augmentation is enabled. Preprocessing involves normalization and (for training mode) random perturbations.
- Parameters:
(....) – See docstring of method
data.dataset.Dataset.input_to_torch_tensor().- Returns:
The given input
xas PyTorch tensor.- Return type:
- plot_sample(image, label=None, figsize=1.5, interactive=False, file_name=None)[source]
Plot a single CIFAR-10 sample.
This method is thought to be helpful for evaluation and debugging purposes.
Deprecated since version 1.0: Please use method
data.dataset.Dataset.plot_samples()instead.- Parameters:
image – A single CIFAR-10 image (given as 1D vector).
label – The label of the given image.
figsize – The height and width of the displayed image.
interactive – Turn on interactive mode. Thus program will run in background while figure is displayed. The figure will be displayed until another one is displayed, the user closes it or the program has terminated. If this option is deactivated, the program will freeze until the user closes the figure.
file_name – (optional) If a file name is provided, then the image will be written into a file instead of plotted to the screen.
- static torch_augment_images(x, device, transform, img_shape=[32, 32, 3])[source]
Augment CIFAR-10 images using a given PyTorch transformation.
- Parameters:
x (numpy.ndarray) – A 2D-Numpy array containing CIFAR-10 images.
device (torch.device or int) – The PyTorch device on which the resulting tensor should be.
transform – A
torchvision.transformsmethod to modify the data.
- Returns:
The augmented images as PyTorch tensor.
- Return type:
- static torch_input_transforms(apply_rand_hflips=True, apply_cutout=False, cutout_length=16, cutout_n_holes=1)[source]
Get data augmentation pipelines for CIFAR-10 inputs.
- Note, the augmentation is inspired by the augmentation proposed in:
Note
We use the same data augmentation pipeline for CIFAR-100, as the images are very similar. Here is an example where they use slightly different normalization values, but we ignore this for now: https://zhenye-na.github.io/2018/10/07/pytorch-resnet-cifar100.html
- Parameters:
apply_rand_hflips (bool) – Apply random horizontal flips during training.
apply_cutout (bool) – Whether the cutout transformation should be applied to training inputs (see class
utils.torch_utils.CutoutTransform).cutout_length (int) – If
apply_cutoutisTrue, then this will be passed as constructor argumentlengthto classutils.torch_utils.CutoutTransform.cutout_n_holes (int) – If
apply_cutoutisTrue, then this will be passed as constructor argumentn_holesto classutils.torch_utils.CutoutTransform.
- Returns:
Tuple containing:
train_transform: A transforms pipeline that applies random transformations and normalizes the image.
test_transform: Similar to train_transform, but no random transformations are applied.
- Return type:
(tuple)
CIFAR-100 Dataset
The module data.cifar100_data contains a handler for the CIFAR 100
dataset.
The dataset consists of 60000 32x32 colour images in 100 classes, with 600 images per class. There are 50000 training images and 10000 test images.
- Information about the dataset can be retrieved from:
- class hypnettorch.data.cifar100_data.CIFAR100Data(data_path, use_one_hot=False, use_data_augmentation=False, validation_size=5000, use_cutout=False)[source]
Bases:
DatasetAn instance of the class shall represent the CIFAR-100 dataset.
- Parameters:
data_path (str) – Where should the dataset be read from? If not existing, the dataset will be downloaded into this folder.
use_one_hot (bool) – Whether the class labels should be represented in a one-hot encoding.
use_data_augmentation (bool) –
Note, this option currently only applies to input batches that are transformed using the class member
input_to_torch_tensor()(hence, only available for PyTorch, so far).Note
If activated, the statistics of test samples are changed as a normalization is applied (identical to the of class
data.cifar10_data.CIFAR10Data).validation_size (int) – The number of validation samples. Validation samples will be taking from the training set (the first
samples).use_cutout (bool) –
Whether option
apply_cutoutshould be set of methodtorch_input_transforms(). We use cutouts of size8 x 8as recommended here.Note
Only applies if
use_data_augmentationis set.
- input_to_torch_tensor(x, device, mode='inference', force_no_preprocessing=False, sample_ids=None)[source]
This method can be used to map the internal numpy arrays to PyTorch tensors.
Note, this method has been overwritten from the base class.
The input images are preprocessed if data augmentation is enabled. Preprocessing involves normalization and (for training mode) random perturbations.
- Parameters:
(....) – See docstring of method
data.dataset.Dataset.input_to_torch_tensor().- Returns:
The given input
xas PyTorch tensor.- Return type:
CUB-200-2011 Dataset
The module data.cub_200_2011_data contains a dataloader for the
Caltech-UCSD Birds-200-2011 Dataset (CUB-200-2011).
The dataset is available at:
For more information on the dataset, please refer to the corresponding publication:
Wah et al., “The Caltech-UCSD Birds-200-2011 Dataset”, California Institute of Technology, 2011. http://www.vision.caltech.edu/visipedia/papers/CUB_200_2011.pdf
The dataset consists of 11,788 images divided into 200 categories. The dataset has a specified train/test split and a lot of additional information (bounding boxes, segmentation, parts annotation, …) that we don’t make use of yet.
Note
This dataset should not be confused with the older version CUB-200, containing only 6,033 images.
Note
We use the same data augmentation as for class
data.ilsvrc2012_data.ILSVRC2012Data.
Note
The original category labels range from 1-200. We modify them to range from 0 - 199.
- class hypnettorch.data.cub_200_2011_data.CUB2002011(data_path, use_one_hot=False, num_val_per_class=0)[source]
Bases:
LargeImgDatasetAn instance of the class shall represent the CUB-200-2011 dataset.
The input data of the dataset will be strings to image files. The output data corresponds to object labels (bird categories).
Note
The dataset will be downloaded if not available.
Note
The original category labels range from 1-200. We modify them to range from 0 - 199.
- Parameters:
data_path (str) – Where should the dataset be read from? If not existing, the dataset will be downloaded into this folder.
use_one_hot (bool) –
Whether the class labels should be represented in a one-hot encoding.
Note
This option does not influence the internal PyTorch Dataset classes (e.g., cmp.
data.large_img_dataset.LargeImgDataset.torch_train), that can be used in conjunction with PyTorch data loaders.num_val_per_class (int) –
The number of validation samples per class. For instance: If value 10 is given, a validation set of size 5 * 200 = 1,000 is constructed (these samples will be removed from the training set).
Note
Validation samples use the same data augmentation pipeline as test samples.
Fashion-MNIST Dataset
The module data.fashion_mnist contains a handler for the
Fashion-MNIST dataset.
The dataset was introduced in:
This module contains a simple wrapper from the corresponding
torchvision dataset to our dataset interface data.dataset.Dataset.
- class hypnettorch.data.fashion_mnist.FashionMNISTData(data_path, use_one_hot=False, validation_size=0, use_torch_augmentation=False)[source]
Bases:
DatasetAn instance of the class shall represent the Fashion-MNIST dataset.
Note
By default, input samples are provided in a range of
[0, 1].- Parameters:
data_path (str) – Where should the dataset be read from? If not existing, the dataset will be downloaded into this folder.
use_one_hot (bool) – Whether the class labels should be represented in a one-hot encoding.
validation_size (int) – The number of validation samples. Validation samples will be taking from the training set (the first
samples).use_torch_augmentation (bool) –
Apply data augmentation to inputs when calling method
data.dataset.Dataset.input_to_torch_tensor().The augmentation will be identical to the one provided by class
data.mnist_data.MNISTData, except that during training also random horizontal flips are applied.Note
If activated, the statistics of test samples are changed as a normalization is applied.
- input_to_torch_tensor(x, device, mode='inference', force_no_preprocessing=False, sample_ids=None)[source]
This method can be used to map the internal numpy arrays to PyTorch tensors.
Note, this method has been overwritten from the base class.
If enabled via constructor option
use_torch_augmentation, input images are preprocessed. Preprocessing involves normalization and (for training mode) random perturbations.- Parameters:
(....) – See docstring of method
data.dataset.Dataset.input_to_torch_tensor().- Returns:
The given input
xas PyTorch tensor.- Return type:
ILSVRC2012 Dataset
The module data.ilsvrc2012_data contains a handler for the Imagenet
Large Scale Visual Recognition Challenge 2012 (ILSVRC2012) dataset, a subset of
the ImageNet dataset:
For more details on the dataset, please refer to:
Olga Russakovsky et al. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision 115, no. 3 (December 1, 2015): 211–52, https://doi.org/10.1007/s11263-015-0816-y
Note
In the current implementation, this handler will not download and extract the dataset for you. You have to do this manually by following the instructions of the README file (which is located in the same folder as this file).
Note
We use the validation set as test set. A new (custom) validation set will
be created by taking the first samples from each training class as
validation samples, where is configured by the user.
Note
This dataset has not yet been prepared for Tensorflow use!
When using PyTorch, this class will create dataset classes
(torch.utils.data.Dataset) for you for the training, testing and
validation set. Afterwards, you can use these dataset instances to create data
loaders:
train_loader = torch.utils.data.DataLoader(
ilsvrc2012_data.torch_train, batch_size=256, shuffle=True,
num_workers=4, pin_memory=True)
You should then use these Pytorch data loaders rather than class internal methods to work with the dataset.
PyTorch data augmentation is applied as defined by the method
ILSVRC2012Data.torch_input_transforms(). Images will be resized and
cropped to size 224 x 224.
- class hypnettorch.data.ilsvrc2012_data.ILSVRC2012Data(data_path, use_one_hot=False, num_val_per_class=0)[source]
Bases:
LargeImgDatasetAn instance of the class shall represent the ILSVRC2012 dataset.
The input data of the dataset will be strings to image files. The output data corresponds to object labels according to the
ILSVRC2012_ID- 1.Note
This is different from many other ILSVRC2012 data handlers, where the labels are computed based on the order of the training folder names (which correspond to WordNet IDs (
WNID)).Note
The dataset has to be already downloaded and extracted before this method can be called. See the local README file for details.
- Parameters:
data_path (str) – Where should the dataset be read from? If not existing, the dataset will be downloaded into this folder.
use_one_hot (bool) –
Whether the class labels should be represented in a one-hot encoding. Note, class labels correspond to the
ILSVRC2012_IDminus 1 (from 0 to 999).Note
This option does not influence the internal PyTorch Dataset classes (e.g., cmp.
data.large_img_dataset.LargeImgDataset.torch_train), that can be used in conjunction with PyTorch data loaders.num_val_per_class (int) –
The number of validation samples per class.
Note
The actual ILSVRC2012 validation set is used as test set by this data handler. Therefore, a new validation set is constructed (if value greater than 0), using the same amount of samples per class. For instance: If value 50 is given, a validation set of size 50 * 1000 = 50,000 is constructed (these samples will be removed from the training set).
Note
Validation samples use the same data augmentation pipeline as test samples.
- to_common_labels(outputs)[source]
Translate between label conventions.
Translate a given set of labels (that correspond to the
ILSVRC2012_ID(minus one) of their images) back to the labels provided by thetorchvision.datasets.ImageFolderclass.Note
This would be the label convention for ImageNet used by PyTorch examples.
- Parameters:
outputs – Targets (as integers or 1-hot encodings).
- Returns:
The translated targets (if the targets where given as 1-hot encodings, then this method also returns 1-hot encodings).
- static torch_input_transforms()[source]
Get data augmentation pipelines for ILSVRC2012 inputs.
- Note, the augmentation is inspired by the augmentation proposed in:
- Returns:
Tuple containing:
train_transform: A transforms pipeline that applies random transformations, normalizes the image and resizes/crops it to a final size of 224 x 224 pixels.
test_transform: Similar to train_transform, but no random transformations are applied.
- Return type:
(tuple)
MNIST Dataset
The module data.mnist_data contains a handler for the MNIST dataset.
The implementation is based on an earlier implementation of a class I used in another project:
Information about the dataset can be retrieved from:
- class hypnettorch.data.mnist_data.MNISTData(data_path, use_one_hot=False, validation_size=5000, use_torch_augmentation=False)[source]
Bases:
DatasetAn instance of the class shall represent the MNIST dataset.
The constructor checks whether the dataset has been read before (a pickle dump has been generated). If so, it reads the dump. Otherwise, it reads the data from scratch and creates a dump for future usage.
Note
By default, input samples are provided in a range of
[0, 1].- Parameters:
data_path (str) – Where should the dataset be read from? If not existing, the dataset will be downloaded into this folder.
use_one_hot (bool) – Whether the class labels should be represented in a one-hot encoding.
validation_size (int) – The number of validation samples. Validation samples will be taking from the training set (the first
samples).use_torch_augmentation (bool) –
Apply data augmentation to inputs when calling method
data.dataset.Dataset.input_to_torch_tensor().The augmentation will withening the inputs according to training image statistics (mean:
0.1307, std:0.3081). In training mode, it will additionally apply random crops.Note
If activated, the statistics of test samples are changed as a normalization is applied.
- input_to_torch_tensor(x, device, mode='inference', force_no_preprocessing=False, sample_ids=None)[source]
This method can be used to map the internal numpy arrays to PyTorch tensors.
Note, this method has been overwritten from the base class.
If enabled via constructor option
use_torch_augmentation, input images are preprocessed. Preprocessing involves normalization and (for training mode) random perturbations.- Parameters:
(....) – See docstring of method
data.dataset.Dataset.input_to_torch_tensor().- Returns:
The given input
xas PyTorch tensor.- Return type:
- static plot_sample(image, label=None, interactive=False, file_name=None)[source]
Plot a single MNIST sample.
This method is thought to be helpful for evaluation and debugging purposes.
Deprecated since version 1.0: Please use method
data.dataset.Dataset.plot_samples()instead.- Parameters:
image – A single MNIST image (given as 1D vector).
label – The label of the given image.
interactive – Turn on interactive mode. Thus program will run in background while figure is displayed. The figure will be displayed until another one is displayed, the user closes it or the program has terminated. If this option is deactivated, the program will freeze until the user closes the figure.
file_name – (optional) If a file name is provided, then the image will be written into a file instead of plotted to the screen.
- static torch_input_transforms(use_random_hflips=False)[source]
Get data augmentation pipelines for MNIST inputs.
- Parameters:
use_random_hflips (bool) –
Also use random horizontal flips during training.
Note
That should not be
Truefor MNIST, since digits loose there meaning when flipped.- Returns:
Tuple containing:
train_transform: A transforms pipeline that applies random transformations and normalizes the image.
test_transform: Similar to train_transform, but no random transformations are applied.
- Return type:
(tuple)
Street View House Numbers (SVHN) Dataset
The module data.svhn_data contains a handler for the
SVHN dataset.
The dataset was introduced in:
Netzer et al., Reading Digits in Natural Images with Unsupervised Feature Learning, 2011.
This module contains a simple wrapper from the corresponding
torchvision
class torchvision.datasets.SVHN to our dataset interface
data.dataset.Dataset.
- class hypnettorch.data.svhn_data.SVHNData(data_path, use_one_hot=False, validation_size=0, use_torch_augmentation=False, use_cutout=False, include_train_extra=False)[source]
Bases:
DatasetAn instance of the class shall represent the SVHN dataset.
Note
By default, input samples are provided in a range of
[0, 1].- Parameters:
data_path (str) – Where should the dataset be read from? If not existing, the dataset will be downloaded into this folder.
use_one_hot (bool) – Whether the class labels should be represented in a one-hot encoding.
validation_size (int) – The number of validation samples. Validation samples will be taking from the training set (the first
samples).use_torch_augmentation (bool) –
Note, this option currently only applies to input batches that are transformed using the class member
input_to_torch_tensor()(hence, only available for PyTorch, so far).The augmentation will be identical to the one provided by class
data.cifar10_data.CIFAR10Data, except that during training no random horizontal flips are applied.Note
If activated, the statistics of test samples are changed as a normalization is applied (identical to the of class
data.cifar10_data.CIFAR10Data).use_cutout (bool) –
Whether option
apply_cutoutshould be set of methodtorch_input_transforms(). We use cutouts of size20 x 20as recommended here.Note
Only applies if
use_data_augmentationis set.include_train_extra (bool) –
The training dataset can be extended by “531,131 additional, somewhat less difficult samples” (see here).
Note, as long as the validation set size is smaller than the original training set size, all validation samples would be taken from the original training set (and thus not contain those “less difficult” samples).
- input_to_torch_tensor(x, device, mode='inference', force_no_preprocessing=False, sample_ids=None)[source]
This method can be used to map the internal numpy arrays to PyTorch tensors.
Note, this method has been overwritten from the base class.
The input images are preprocessed if data augmentation is enabled. Preprocessing involves normalization and (for training mode) random perturbations.
- Parameters:
(....) – See docstring of method
data.dataset.Dataset.input_to_torch_tensor().- Returns:
The given input
xas PyTorch tensor.- Return type:
Udacity Self-Driving Car Challenge 2 - Steering Angle Prediction
The module udacity_ch2 contains a handler for the
Udacity Self-Driving Car Challenge 2, which contains
imagery from a car’s frontal center camera in combination with CAN recorded
steering angles (the actual dataset contains more information, but those
ingredients are enough for the steering angle prediction task).
Note
In the current implementation, this handler will not download and extract the dataset for you. You have to do this manually by following the instructions of the README file (which is located in the same folder as this file).
When using PyTorch, this class will create dataset classes
(torch.utils.data.Dataset) for you for the training, testing and
validation set. Afterwards, you can use these dataset instances to create data
loaders:
train_loader = torch.utils.data.DataLoader(
udacity_ch2.torch_train, batch_size=256, shuffle=True,
num_workers=4, pin_memory=True)
You should then use these Pytorch data loaders rather than class internal methods to work with the dataset.
PyTorch data augmentation is applied as defined by the method
UdacityCH2Data.torch_input_transforms().
- class hypnettorch.data.udacity_ch2.UdacityCh2Data(data_path, num_val=0)[source]
Bases:
LargeImgDatasetAn instance of the class is representing the Udacity Ch2 dataset.
The input data of the dataset will be strings to image files. The output data corresponds to steering angles.
Note
The dataset has to be already downloaded and extracted before this method can be called. See the local README file for details.
- Parameters:
data_path (str) – Where should the dataset be read from? The dataset folder is expected to contain the subfolders
Ch2_001(test set) andCh2_002(train and validation set). See README for details.num_val (int) –
The number of validation samples. The validation set will be random subset of the training set. Validation samples are excluded from the training set!
Note
Validation samples use the same data augmentation pipeline as test samples.
- property test_angles_available
Whether the test angles are available.
Note
If not available, test angles will all be set to zero!
The original dataset comes only with test images. However, the test set was later released too, which contains both images and angles. See the README for details.
- Type:
Sequential, custom and special datasets
See documentation of subpackages special and timeseries.