Timeseries Datasets
Common Datasets
Dataset for the sequential copy task
A data handler for the copy task as described in:
A typical usecase of this dataset is in an incremental learning setting. For instance, a sequence of tasks with increasing lengths can be used in curriculum learning or continual learning.
The class contains a lot of options to modify the basic copy task. Many of those variations target the usecase continual learning (rather than curriculum learning) by providing sets of distinct tasks with comparable difficulty. Note, these variations typically extend the required input processing and are not limited to plain copying.
- class hypnettorch.data.timeseries.copy_data.CopyTask(min_input_len, max_input_len, seq_width=7, out_width=-1, num_train=100, num_test=100, num_val=None, pat_len=-1, scatter_pattern=False, permute_width=False, permute_time=False, permute_xor=False, permute_xor_iter=1, permute_xor_separate=False, random_pad=False, pad_after_stop=False, pairwise_permute=False, revert_output_seq=False, rseed=None, rseed_permute=None, rseed_scatter=None)[source]
Bases:
SequentialDatasetData handler for the sequential copy task.
In this task, a binary vector is presented as input, and the network has to learn to copy it. Such that the network cannot rely on intermediate information, there is a delay between the end of the input presentation and the output generation. The end of the input sequence is delimited by a binary bit, which is always zero except when the sequence finishes. This flag should not be copied.
An instance of this class will represent copy task patterns of random length (by default) but fixed width (but see option
out_width). The length of input patterns will be sampled uniformly from the interval[min_input_len, max_input_len]. Note that the actual length of the patternspat_lenmight be smaller in the case where there are a certain number of zero-valued timesteps within the input. As such, every sequence is characterised by the following values:pat_len: the actual length of the binary pattern to be copied. Across this duration, half the pixels have value of 1 and the other half have value 0.input_len: the length of input presentation up until the stop flag. It is equal to the pattern length plus the number of zero-valued timesteps.seq_len: the length of the entire sequences, including input presentation, stop flag and output generation. Therefore it is equal to the input length, plus one (stop flag), plus the pattern length (since during output reconstruction we don’t care about reconstructing the zero-valued part of the input).
Caution
Manipulations such as permutations or scattering/masking will be applied online in
output_to_torch_tensor().- Parameters:
min_input_len (int) –
The minimum length of an input sequence.
Note
The input length is the length of the presented input before the stop flag. It might include both a pattern to be copied and a set of zero-valued timesteps that do not need to be reconstructed.
max_input_len (int) – The maximum length of a pattern.
seq_width (int) –
The width if each pattern.
Note
Each pattern will have a certain length (across time) and a certain width.
out_width (int, optional) – If specified, a number smaller than
seq_widthis expected. In this case, only the firstout_widthinput features are expected to be copied (i.e., only those occur as target output features).num_train (int) – Number of training samples.
num_test (int) – Number of test samples.
num_val (int, optional) – Number of validation samples.
pat_len (int, optional) –
The actual length of the pattern within the input sequence (excluding zero-valued timesteps). By default, the value is
-1meaning that the pattern length is identical to the input length, and there are no zeroed timesteps. For other values, the input sequences will be zero-padded afterpat_lentimesteps. Therefore, the input sequence lengths remain the same, but the actual duration of the patterns is reduced. This manipulation is useful to decouple sequence length and memory requirement for analysis.Note
We define the number of timesteps that are not zero, and therefore for values different than
-1with the current implementation we will obtain patterns of identical length (but different input sequence length).scatter_pattern (bool) – Option only compatible with
pat_len != -1. If activated, the pattern is not concentrated at the beginning of the input sequence. Instead, the whole input sequence will be filled with a random pattern (i.e., no padding is used) but only a fixed and random (see optionrseed_scatter) number of timesteps from the input sequence are considered to create an output sequence of lengthpat_len.permute_width (boolean, optional) – If enabled, the generated pattern will be permuted along the width axis.
permute_time (boolean, optional) – If enabled, the generated pattern will be permuted along the temporal axis.
permute_xor (bool) – Only applicable if
permute_widthorpermute_timeisTrue. IfTrue, the permuted and unpermuted output pattern will be combined to a new output pattern via a logical xor operation.permute_xor_iter (int) – Only applicable if
permute_xoris set. IfTrue, the internal permutation is applied iteratively and XOR-ed with the previous target output to obtain a final target output.permute_xor_separate (bool) –
Only applicable if
permute_xoris set andpermute_xor_iter > 1. IfTrue, a separate permutation matrix is used per iteration described bypermute_xor_iter. In this case, we the input pattern ispermute_xor_itertimes permuted via a separate permutation matrix and the resulting patterns are sequentially XOR-ed with the original input pattern.Hence, this can be viewed as follows:
permute_xor_iterrandom input pixels are assigned to each output pattern pixel. This output pattern pixel will be1if and only if the number of ones in those input pixels is odd.random_pad (bool, optional) – If activated, the truncated part of the input (see option
pat_len) will be left as a random pattern, and not set to zero. Note that the loss computation is unaffected by this option.pad_after_stop (bool) – This option will affect how option
pat_lenis handled and therefore can only be used ifpat_lenis set. IfTrue,pat_lenwill determine the length of the input sequence (no padding applied before the stop bit). Therefore, the padding is moved to after the stop bit and therewith part of the target output. I.e., the original input sequence length determines the output sequence length which consists of zero padding and the input pattern of lengthpat_len. Note, in this case, the optionsmin_input_lenandmax_input_lenactually apply solely to the output.pairwise_permute (bool, optional) – This option is only used if some permutation is activated. If enabled, it will force the permutation to be a pairwise switch between successive pixels. Note that this operation is deterministic, and will therefore be identical for different tasks, if more than one task is generated.
revert_output_seq (bool, optional) – If enabled, it will revert output sequences along the time dimension. Note that this operation is deterministic, and will therefore be identical for different tasks, if more than one task is generated.
rseed (int, optional) – If
None, the current random state of numpy is used to generate the data. Otherwise, a new random state with the given seed is generated.rseed_permute (int, optional) – Random seed for performing permutations of the copy patterns. Only used if option
permute_widthorpermute_timeare activated. IfNone, the current random state of numpy is used to generate the data. Otherwise, a new random state with the given seed is generated.rseed_scatter (int, optional) – See option
rseed. Random seed for determining which timesteps of the input sequence to use for the output pattern if optionscatter_patternis activated.
- static create_permutation_matrix(permute_time, permute_width, pat_len_perm, seq_width, rstate_permute, pairwise_permute=False, revert_output_seq=False)[source]
Create a permutation matrix.
- Parameters:
pairwise_permute (boolean, optional) – If True, the permutations correspond to switching the position of neighboring pixels. For example 1234567 would become 2143657. If the number of timesteps is odd, the last timestep is left unmoved.
revert_output_seq (boolean, optional) – If True, the output sequences will be inverted along the time dimension. I.e. a pattern 1234567 would become 7654321.
- get_out_pattern_bounds(sample_ids)[source]
Get the start time step and length of the output pattern within the sequence.
Note, input sequences may have varying length (even though they are padded to the same length). Assume we are considering a input of length 7, meaning that the total sequence would have the length 15 = 7 + 1 + 7 (input pattern presentation, stop bit, output pattern copying). In addition, assume that the maximum input length is 10 (hence, the maximum input length is 21 = 10 + 1 + 10). In this case, all sequences are padded to have length 21. For the sample in consideration (with input length 7), the output pattern sequence starts at index 8 and has a length of 7, or less, if the input contains some zeroed values. Hence, these two number would be returned for this sample.
- Parameters:
(....) – See docstring of method
data.sequential_data.SequentialDataset.get_in_seq_lengths().- Returns:
Tuple containing:
start_inds (numpy.ndarray): 1D array with the same length as
sample_ids, which contains the start index for output pattern in a given sample.lengths (numpy.ndarray): 1D array containing the lengths of the pattern per given sample.
- Return type:
(tuple)
- get_zeroed_ts(sample_ids)[source]
Get the number of zeroed timesteps in each input pattern.
Note, if
scatter_patternwas activated in the constructor, then this number does not refer to the number of padded steps in the input sequence but rather to the number of unused steps in the input sequence. However, those unused steps will still contain random patterns. Similarly, if argumentrandom_padis used.Note, if
pad_after_stopwas activated, then the zeroed timesteps actually occur after the stop bit, i.e., in the output part of the sequence.- Parameters:
(....) – See docstring of method
get_in_seq_lengths().- Returns:
A 1D numpy array.
- Return type:
- output_to_torch_tensor(*args, **kwargs)[source]
Similar to method
input_to_torch_tensor(), just for dataset outputs.- Parameters:
(....) – See docstring of method
data.dataset.Dataset.output_to_torch_tensor().- Returns:
The given input
yas PyTorch tensor. It has dimensions[T, B, *out_shape], whereTis the number of time steps (see attributemax_num_ts_out),Bis the batch size andout_shaperefers to the output feature shape, seedata.dataset.Dataset.out_shape.- Return type:
- property permutation
Getter for attribute
permutation_
Multilingual universal Dependencies Dataset
A data handler for the multilingual universal dependencies dataset:
This dataset is a Part-of-Speech tagging dataset that assigns to each token in a sentence one of a set of universal syntactic tags. We adapt this dataset to a Continual Learning scenario by considering Part-of-Speech tagging in different languages as different tasks.
- class hypnettorch.data.timeseries.mud_data.MUDData(task_data, vocabulary=None, tagset=None)[source]
Bases:
SequentialDatasetDatahandler for the multilingual universal dependencies dataset.
- Parameters:
task_data – A preprocessed dataset structure. Please use function
get_mud_handlers()to create instances of this class.vocabulary (list or tuple, optional) – The vocabular, i.e., a list of words that allows us to decode input sentences.
- decode_batch(inputs, outputs, sample_ids=None)[source]
Decode a batch of input and output samples into strings.
This method translates a batch of input and output sequences (consisting of vocabulary and tagset indices) into actual sentences consisting of strings.
Note
This method is only applicable if
vocabularyandtagsetwere provided to the constructor.- Parameters:
inputs (numpy.ndarray or torch.Tensor) – Input samples as provided to or returned from method
input_to_torch_tensor().outputs (numpy.ndarray or torch.Tensor) – Output samples as provided to or returned from method
output_to_torch_tensor().sample_ids (numpy.ndarray) – See method
train_ids_to_indices(). If provided, the returned sentences are cropped to the actual sequence length.
- Returns:
Tuple containing:
in_words (list): List of list of strings, where each string corresponds to a word in the corresponding input sentence of
inputs.out_tags (list): List of list of strings, where each string corresponds to the output tag corresponding to the tag ID read from
outputs.
- Return type:
(tuple)
- input_to_torch_tensor(x, device, mode='inference', force_no_preprocessing=False, sample_ids=None)[source]
This method can be used to map the internal numpy arrays to PyTorch tensors.
Note
If
sample_idsare provided, then padding will be reduced according to the sample within the minibatch with the longest sequence length.- Parameters:
(....) – See docstring of method
data.dataset.Dataset.input_to_torch_tensor().- Returns:
See docstring of method
data.sequential_dataset.SequentialDataset.input_to_torch_tensor().- Return type:
(torch.LongTensor)
- output_to_torch_tensor(y, device, mode='inference', force_no_preprocessing=False, sample_ids=None)[source]
Identical to method
data.sequential_dataset.SequentialDataset.output_to_torch_tensor().However, if
sample_idsare provided, then the same padding behavior as elicited by methodinput_to_torch_tensor()is performed.
- hypnettorch.data.timeseries.mud_data.get_mud_handlers(data_path, num_tasks=5)[source]
This function instantiates
num_tasksobjects of the classMUDDataeach of which will contain a PoS dataset for a different language.
Dataset for the Audioset task
A data handler for the audioset dataset taken from:
Data were preprocessed with the script
data.timeseries.structure_audioset and then uploaded to
dropbox. If this link becomes invalid, the data has to
be preprocessed from scratch.
- class hypnettorch.data.timeseries.audioset_data.AudiosetData(data_path, use_one_hot=True, validation_size=0, target_per_timestep=True, rseed=None)[source]
Bases:
SequentialDatasetDatahandler for the audioset task.
- Parameters:
data_path (str) – Where should the dataset be read from? If not existing, the dataset will be downloaded into this folder.
use_one_hot (bool) – Whether the class labels should be represented in a one-hot encoding.
validation_size (int) – The number of validation samples.
target_per_timestep (bool, optional) – If activated, the one-hot encoding of the current image will be copied across the entire sequence. Else, there is a single target for the entire sequence (rather than one per timestep.
rseed (int, optional) – If
None, the current random state of numpy is used to select a validation set from the training data. Otherwise, a new random state with the given seed is generated.
Stroke MNIST (SMNIST) Dataset
A data handler for the stroke mnist data as discribed here:
The data was preprocessed with the script
data.timeseries.preprocess_smnist and then uploaded to
dropbox. If
this link becomes invalid, the data has to be preprocessed from scratch.
- class hypnettorch.data.timeseries.smnist_data.SMNISTData(data_path, use_one_hot=False, validation_size=0, target_per_timestep=True)[source]
Bases:
SequentialDatasetDatahandler for stroke MNIST.
Note
That the outputs are always provided as one-hot encodings of duration equal to one. One can decide to make these targets span the entirety of the sequence (by repeating it over timesteps) by setting
target_per_timesteptoTrue.- Parameters:
data_path (str) – Where should the dataset be read from? If not existing, the dataset will be downloaded into this folder.
use_one_hot (bool) – Whether the class labels should be represented in a one-hot encoding.
validation_size (int) – The number of validation samples. Validation samples will be taking from the training set (the first
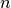 samples).
samples).target_per_timestep (bool) – If activated, the one-hot encoding of the current image will be copied across the entire sequence. Else, there is a single target for the entire sequence (rather than one per timestep.
Custom Datasets
Dataset from random recurrent teacher networks
We consider a student-teacher setup. The dataset is meant for continual learning, such that an individual teacher (individual task) is used to determine the computation of a subspace of the activations of a recurrent student network.
This is a synthetic dataset that will allow the manual construction of the optimal student network that solves all tasks simultanously. As such, this student network can be compared to trained networks (either continually or in parallel on multiple tasks).
To be more precise, we set the teacher to be an Elman-type recurrent network
(see mnets.simple_rnn.SimpleRNN):
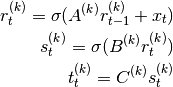
Where 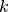 is a unique task identifier (in the context of multiple
teachers),
is a unique task identifier (in the context of multiple
teachers), 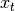 is the network input at time
is the network input at time 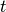 , the recurrent
state is initialized at zero
, the recurrent
state is initialized at zero 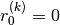 and
and 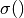 is a
user-defined non-linearity. The non-linear output computation
is a
user-defined non-linearity. The non-linear output computation 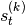 is optional.
is optional.
We assume an input 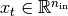 and a target
dimensionality of
and a target
dimensionality of 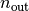 .
.
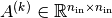 ,
,
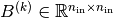 and
and
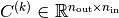 are random
matrices that determine the teacher network’s input-output mapping.
are random
matrices that determine the teacher network’s input-output mapping.
Having a task setup like this one can manually construct an RNN network that can solve multiple of such tasks to perfection (assuming a task-specific output head). For instance, consider the following Elman-type RNN with task-specific output head.
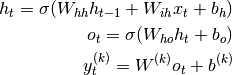
With 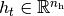 being the hidden state (we also
assume
being the hidden state (we also
assume 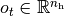 ).
).
We can assign this network the following weights to ensure that all 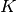 tasks are solved to perfection:
tasks are solved to perfection:
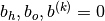
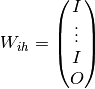 where
where
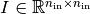 refers to the
identity matrix that simply copies the input into separate subspaces of the
hidden state
refers to the
identity matrix that simply copies the input into separate subspaces of the
hidden stateThe hidden-to-hidden weights would be block diagonal:
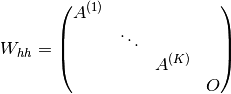
The hidden-to-output weights would be block diagonal:
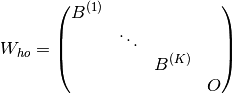
The task-specific output matrix would be
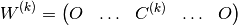
- class hypnettorch.data.timeseries.rnd_rec_teacher.RndRecTeacher(num_train=1000, num_test=100, num_val=None, n_in=7, n_out=7, sigma='tanh', mat_A=None, mat_B=None, mat_C=None, orth_A=False, rank_A=-1, max_sv_A=-1.0, no_extra_fc=False, inputs=None, input_range=(-1, 1), n_ts_in=10, n_ts_out=-1, rseed=None)[source]
Bases:
SequentialDatasetCreate a dataset from a random recurrent teacher.
- Parameters:
num_train (int) – Number of training samples.
num_test (int) – Number of test samples.
num_val (int, optional) – Number of validation samples.
n_in (int) – Dimensionality of inputs
.n_out (int) – Dimensionality of outputs
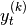 .
.sigma (str) –
Name of the nonlinearity
to be used.'linear''sigmoid''tanh'
mat_A (numpy.ndarray, optional) – A numpy array of shape
[n_in, n_in]representing matrix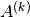 . If not
specified, a random matrix will be generated.
. If not
specified, a random matrix will be generated.mat_B (numpy.ndarray, optional) – A numpy array of shape
[n_in, n_in]representing matrix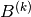 . If not
specified, a random matrix will be generated.
. If not
specified, a random matrix will be generated.mat_C (numpy.ndarray, optional) – A numpy array of shape
[n_out, n_in]representing matrix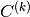 . If not
specified, a random matrix will be generated.
. If not
specified, a random matrix will be generated.orth_A (bool) – If
is randomly generated and this option
is activated, then will be initialized as an
orthogonal matrix.rank_A (int, optional) – The rank of the randomly generated matrix
. Note, this option is mutually exclusive with
option orth_A.max_sv_A (float, optional) – The maximum singular value of the randomly generated matrix
. Note, this option is mutually
exclusive with option orth_A.no_extra_fc –
If
True, the hidden fully-connected layer using matrix will be omitted when computed targets from the
teacher. Hence, the teacher computation becomes: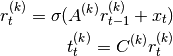
inputs (numpy.ndarray, optional) – The inputs
to be used.
Has to be an array of shape [n_ts_in, N, n_in]withN = num_train + num_test + (0 if num_val is None else num_val).input_range (tuple) – Tuple of integers. Used as ranges for a uniform distribution from which input samples
are drawn.n_ts_in (int) – The number of input timesteps.
n_ts_out (int, optional) – The number of output timesteps. Can be greater than
n_ts_in. In this case, the inputs at time greater thann_ts_inwill be zero.rseed (int, optional) – If
None, the current random state of numpy is used to generate the data. Otherwise, a new random state with the given seed is generated.
- static construct_ideal_student(net, dhandlers)[source]
Set the weights of an RNN such that it perfectly solves all tasks represented by the teachers in
dhandlers.Note
This method only works properly if the RNN
netis properly setup such that its computation resembles the target computation of the individual teachers. I.e., an ideal student can be constructed by only modifying the weights.- Parameters:
net (mnets.simple_rnn.SimpleRNN) –
The student RNN whose weights will be overwritten. Importantly, this method does not ensure that the teacher computation is compatible with the given student network.
Note
The internal weights of the network are modified in-place.
dhandlers (list) – List of datasets from teachers (i.e., instances of class
RndRecTeacher). The RNNnetmust have at least as many output heads aslen(dhandlers).
- property mat_A
The teacher matrix
.- Type:
- property mat_B
The teacher matrix
.- Type:
- property mat_C
The teacher matrix
.- Type:
Continual Learning Datasets
Set of cognitive tasks
A data handler for cognitive tasks as implemented in Masse et al (PNAS). The user can construct individual datasets with this data handler and use each of these datasets to train a model in a continual leraning setting.
- class hypnettorch.data.timeseries.cognitive_tasks.cognitive_data.CognitiveTasks(task_id=0, num_train=80, num_test=20, num_val=None, rstate=None)[source]
Bases:
DatasetAn instance of this class shall represent a one of the 20 cognitive tasks.
Generate a new dataset.
We use the MultiStimulus class from Masse el al. to genereate the inputs and outputs of different cognitive tasks in accordance with the data handling structures of the hnet code base.
Note that masks (part of the Masse et al. trial generator) will be handled independently of this data handler.
- Parameters:
- input_to_torch_tensor(x, device, mode='inference', force_no_preprocessing=False, sample_ids=None)[source]
This method can be used to map the internal numpy arrays to PyTorch tensors.
- Parameters:
(....) – See docstring of method
data.dataset.Dataset.input_to_torch_tensor().- Returns:
The given input
xas 3D PyTorch tensor. It has dimensions[T, B, N], whereTis the number of time steps per stimulus,Bis the batch size andNthe number of input units.- Return type:
- output_to_torch_tensor(y, device, mode='inference', force_no_preprocessing=False, sample_ids=None)[source]
Similar to method
input_to_torch_tensor(), just for dataset outputs.- Parameters:
(....) – See docstring of method
data.dataset.Dataset.output_to_torch_tensor().- Returns:
A tensor of shape
[T, B, C], whereTis the number of time steps per stimulus,Bis the batch size andCthe number of classes.- Return type:
Sequence of Stroke MNIST Samples (SeqSMNIST) Dataset
A data handler to generate a set of sequential stroke MNIST tasks for continual
learning. The used stroke MNIST data was already preprocessed with the script
data.timeseries.preprocess_smnist (see also the corresponding data
handler in data.timeseries.smnist_data).
The task
Given a sequence of two smnist digits of length n (e.g. 2,5,5,2,2 with
n=5), classify which of the 2**n possible binary sequences (classes) the
presented sequence belongs to. E.g., for n=3 the number of classes would be
8 (corresponding to all possible sequences with two digits (0 and 1
here): 000, 001, 010, 100, 011, 110, 101, 111.
The individual tasks of the task family differ in which digits are used to generate the binary sequences. Considering all possible pairs of digits we can generate (10**2-10) / 2 = 45 tasks.
- class hypnettorch.data.timeseries.seq_smnist.SeqSMNIST(data_path, use_one_hot=True, num_train=1600, num_test=400, num_val=0, target_per_timestep=True, sequence_length=4, digits=(0, 1), two_class=False, upsample_control=False, fix_class_partition=False, rseed=None)[source]
Bases:
SequentialDatasetDatahandler for one sequential stroke MNIST task (as described above).
Note
That the outputs are always provided as one-hot encodings of duration equal to one. One can decide to make these targets span the entirety of the sequence (by repeating it over timesteps) by setting
target_per_timesteptoTrue.- Parameters:
data_path (str) – Where should the dataset be read from? If not existing, the dataset will be downloaded into this folder.
use_one_hot (bool) – Whether the class labels should be represented in a one-hot encoding.
num_train (int) – Number of training samples to be generated.
num_test (int) – Number of test samples to be generated.
num_val (int) – Number of validation samples to be generated.
target_per_timestep (bool) – If activated, the one-hot encoding of the current image will be copied across the entire sequence. Else, there is a single target for the entire sequence (rather than one per timestep.
sequence_length (int) – The length of the binary sequence to be classified. This also affects the number of classes which is
2**n.digits (tuple) – The two digits that shall be used for generating the binary sequence.
two_class (bool) – When true, instead of classifying each possible sequence individually, sequences are randomly grouped into two classes. This makes the number of classes (and therefore the chance level) independent of the sequence length.
upsample_control (bool) – If
True, instead of building sequences of digits, we upsample single digits by a factor given byseq_len.fix_class_partition (bool) – TODO
rseed (int) – Seed for numpy random state.
Split Audioset Dataset
The module data.timeseries.split_audioset contains a wrapper for data
handlers for the SplitAudioset task.
It is based on the module data.special.split_mnist.
- class hypnettorch.data.timeseries.split_audioset.SplitAudioset(data_path, use_one_hot=True, validation_size=1000, target_per_timestep=True, rseed=None, labels=[0, 1], full_out_dim=False)[source]
Bases:
AudiosetDataAn instance of the class shall represent a SplitAudioset task.
- Parameters:
(....) – See docstring of class
data.timeseries.audioset_data.AudiosetData.validation_size (int) – The size of the validation set of each individual data handler.
labels (list) – The labels that should be part of this task.
full_out_dim (bool) – Choose the original Audioset labels instead of the new task output dimension. This option will affect the attributes
data.dataset.Dataset.num_classesanddata.dataset.Dataset.out_shape.
- transform_outputs(outputs)[source]
Transform the outputs from the 100D Audioset dataset into proper labels based on the constructor argument
labels.I.e., the output will have
len(labels)classes.Example
Split with labels [2,3]
1-hot encodings: [0,0,0,1,…,0,0,0,0,0,0] -> [0,1]
labels: 3 -> 1
- Parameters:
outputs – 2D numpy array of outputs.
- Returns:
2D numpy array of transformed outputs.
- hypnettorch.data.timeseries.split_audioset.get_split_audioset_handlers(data_path, use_one_hot=True, validation_size=0, target_per_timestep=True, num_classes_per_task=10, num_tasks=5, rseed=None)[source]
This function instantiates
num_tasksobjects of the classAudiosetDatawhich will contain a disjoint set of labels.The SplitAudioset task consists of
num_taskstasks which consist of a classification problem withnum_classes_per_taskclasses from our preprocessed Audioset data set.- Parameters:
(....) – See docstring of class
data.timeseries.audioset_data.AudiosetData.validation_size (int) – The size of the validation set of each individual data handler.
num_classes_per_task (int) – Number of classes to put into one data handler. If
2, then every data handler will include 2 classes.num_tasks (int) – The number of data handlers that should be returned by this function.
rseed (int, optional) – The
rseedis passed when constructing instances of classSplitAudioset. In addition, it is used to shuffle the classes before splitting Audioset into tasks.
- Returns:
A list of data handlers, each corresponding to a
SplitAudiosetobject.- Return type:
(list)
Split SMNIST Dataset
The module data.timeseries.split_smnist contains a wrapper for data
handlers for a set of SplitSMNIST tasks (a partitioning of classes from the
data.timeseries.smnist_data.SMNISTData dataset).
The implementation is based on the module data.special.split_mnist.
- class hypnettorch.data.timeseries.split_smnist.SplitSMNIST(data_path, use_one_hot=False, validation_size=1000, target_per_timestep=True, labels=[0, 1], full_out_dim=False)[source]
Bases:
SMNISTDataAn instance of the class shall represent a SplitSMNIST task.
- Parameters:
data_path (str) – See argument
data_pathof classdata.timeseries.smnist_data.SMNISTData.use_one_hot (bool) – Whether the class labels should be represented in a one-hot encoding.
validation_size (int) – The number of validation samples. Validation samples will be taken from the training set (the first
samples).target_per_timestep (str) – See argument
target_per_timestepof classdata.timeseries.smnist_data.SMNISTData.labels (list) – The labels that should be part of this task.
full_out_dim (bool) – Choose the original SMNIST instead of the new task output dimension. This option will affect the attributes
data.dataset.Dataset.num_classesanddata.dataset.Dataset.out_shape.
- transform_outputs(outputs)[source]
Transform the outputs from the 10D MNIST dataset into proper labels based on the constructor argument
labels.I.e., the output will have
len(labels)classes.Example
Split with labels [2,3]
1-hot encodings: [0,0,0,1,0,0,0,0,0,0] -> [0,1]
labels: 3 -> 1
- Parameters:
outputs – 2D numpy array of outputs.
- Returns:
2D numpy array of transformed outputs.
- hypnettorch.data.timeseries.split_smnist.get_split_smnist_handlers(data_path, use_one_hot=True, validation_size=0, target_per_timestep=True, num_classes_per_task=2, num_tasks=None)[source]
This function instantiates 5 objects of the class
SplitSMNISTwhich will contain a disjoint set of labels.The SplitSMNIST task consists of 5 tasks corresponding to stroke trajectories for the images with labels [0,1], [2,3], [4,5], [6,7], [8,9].
- Parameters:
data_path (str) – See argument
data_pathof classdata.timeseries.smnist_data.SMNISTData.use_one_hot (bool) – Whether the class labels should be represented in a one-hot encoding.
validation_size (int) – The size of the validation set of each individual data handler.
target_per_timestep (str) – See argument
target_per_timestepof classdata.timeseries.smnist_data.SMNISTData.num_classes_per_task (int) – Number of classes to put into one data handler. If
2, then every data handler will include 2 digits.num_tasks (int, optional) – The number of data handlers that should be returned by this function.
- Returns:
- A list of data handlers, each corresponding to a
SplitSMNISTobject.
- Return type:
(list)